NLP Exploration by Analyzing Tim Ferriss Transcripts Using R

Source: Nuance.com
Tim Ferriss is one of my favorite podcasters. Last year, he posted transcripts to all of his episodes. As a student of data science and machine learning, I thought it would be cool to do a natural language processing (NLP) project on his podcast.
Disclaimers: this blog post is not a how to on NLP, nor is it what I would consider to be a final version of a topic modeling of Tim Ferriss’s podcast. Instead, this is a prototype for proof of concept.
This project is me having some fun during my spare time exploring NLP by analyzing a podcast I enjoy and am already familiar with. I spent between 30 and 60 minutes per day about three times per week during the past few weeks working on this. I plan on updating this analysis in a future post, and will write a separate but related post on why we should have hobbies that we tend to frequently.
Downloading and Reading PDFs
Tim Ferriss posted transcripts in two formats: PDF and web. For this prototype, I analyzed the first ~150 episodes, which are in the PDF form. The first script I wrote downloads these PDFs. I also created a list of stop words comprised of words in episode titles. I did this to remove guest names from the analysis. Proper names tend to be less common and mentioned frequently in the episodes, which might result in the algorithm giving high importance to guests’ names. Once I had these PDFs stored, I then wrote a script to read them. The code below is an excerpt from the PDF download script, which created the list of stop words based on episode titles.
# stopwords for future
linkStopWords <- pdfNames[-grep("tim-ferriss", pdfNames)]
linkStopWords <- gsub("[0-9]+", "", linkStopWords)
linkStopWords <- gsub("---", "", linkStopWords)
linkStopWords <- gsub(".pdf", "", linkStopWords)
linkStopWords <- strsplit(linkStopWords, split = "-")
linkStopWords <- sort(unique(unlist(linkStopWords)))Manual Stop Words List
The algorithm gave importance to a few words that showed up in many topics, which to me seemed to muddy the distinction among the topics. I created a manual list of stop words, shown below.
# manual stop words
timFerrissStopWords <- c("copyright",
"reserved",
"tim",
"ferriss",
"podcast",
"2018",
"2007",
"voice",
"male",
"inaudible",
# start here are words after iterating thru topics
"people",
"yeah",
"lot",
"time",
"rights",
"book",
"life",
"sort",
"ferris",
"world",
"love",
"stuff",
"d'agostino",
"guy",
"guys",
"person",
"mager",
"start",
"started")One potential takeaway is that many episodes cover topics like social (e.g., people and love), travel (e.g., world), and productivity (e.g., time).
Topics
After finding important words for each document, I turned to topic modeling. I manually iterated through a variety of potential count of topics (from two to 10), displaying anywhere from five to 20 words. I eventually settled on six topics showing the top 15 words (shown below). Having listened to my fair share of Tim Ferriss podcast episodes, I thought these six topics were reasonable: Creativity, Psychology, Fitness, Health, Mindfulness, and Business. It might be important to note that the algorithm abstracts topics; I labeled each of the six topics based on the important words that the algorithm thought were associated with each topic.
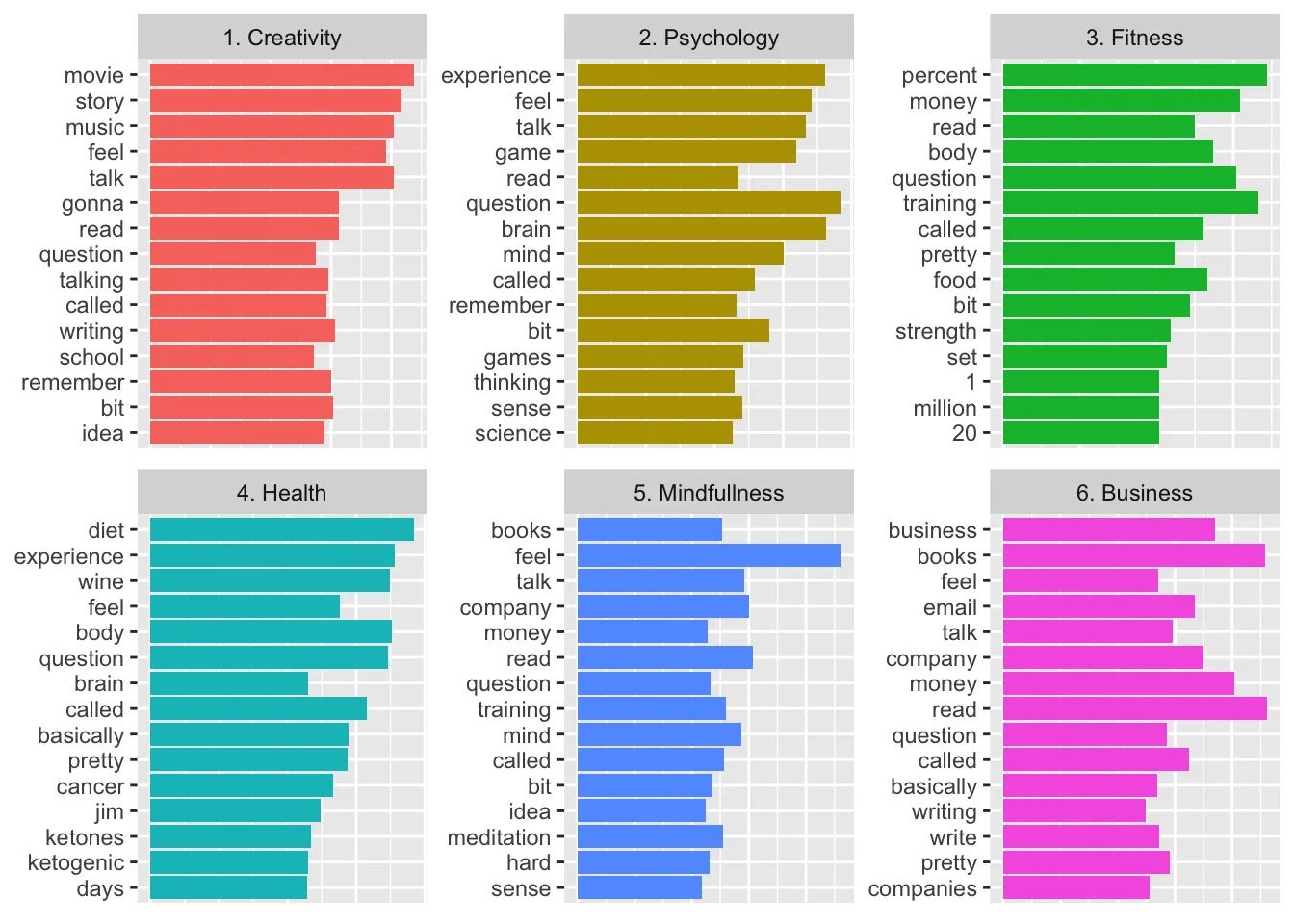
I’ve purposely omitted the x-axis label here, which is the beta coefficient for each word. The bigger the bar, the more important it is for that topic.
Examples
Preliminarily satisfied with these six topics, I wanted to see how these looked against actual episodes. I picked episodes that I’ve listened to, or guests who I recognized. I categorized these episodes loosely into (1) fitness and health, (2) entertainment, or what I think is related to the “Creativity” topic, or (3) random (basically I wasn't sure how I might categorize them).
# test a few that i've listened to
fitnessAndHealth <- c("kellystarrett",
"rhondapatrick",
"arnoldschwarzenegger")
[...]
entertainment <- c("arnoldschwarzenegger",
"jamiefoxx",
"costner",
"bjnovak",
"sethrogen",
"jonfavreau")
[...]
randomPodcasts <- c("jocko",
"samharris",
"stephendubner",
"random") Output
The tables below show the top two topics predicted for each episode. The topic modeling seemed to do pretty decently. Most of the episodes that I thought would be related to fitness and health were nearly 100% distributed to either Fitness or Health.
# A tibble: 10 x 3
title percent topic
<chr> <dbl> <fct>
1 20180703kellystarrettandjustinmegar.pdf 76 4. Health
2 20180703kellystarrettandjustinmegar.pdf 24 3. Fitness
3 20180760arnoldschwarzenegger.pdf 68 3. Fitness
4 20180760arnoldschwarzenegger.pdf 32 1. Creativity
5 20180764kellystarrett.pdf 99 3. Fitness
6 20180764kellystarrett.pdf 1 4. Health
7 20180912rhondapatrick.pdf 72 3. Fitness
8 20180912rhondapatrick.pdf 28 4. Health
9 20180985kellystarrett.pdf 100 3. Fitness
10 20180985kellystarrett.pdf 0 5. MindfullnessArnold’s episode was a bit of an aberration relative to the other episodes. His second highest rated topic was Creativity, which is why I also included that episode in the Entertainment category.
# A tibble: 12 x 3
title percent topic
<chr> <dbl> <fct>
1 20180760arnoldschwarzenegger.pdf 68 3. Fitness
2 20180760arnoldschwarzenegger.pdf 32 1. Creativity
3 201808119kevincostner.pdf 100 1. Creativity
4 201808119kevincostner.pdf 0 6. Business
5 201808121bjnovak.pdf 73 1. Creativity
6 201808121bjnovak.pdf 27 5. Mindfullness
7 201808124jamiefoxx.pdf 100 1. Creativity
8 201808124jamiefoxx.pdf 0 3. Fitness
9 201809108sethrogenevangoldberg.pdf 100 1. Creativity
10 201809108sethrogenevangoldberg.pdf 0 5. Mindfullness
11 20180971jonfavreau.pdf 100 1. Creativity
12 20180971jonfavreau.pdf 0 6. Business The final list of manually selected episodes had the most variety of the three manually selected groups.
# A tibble: 16 x 3
title percent topic
<chr> <dbl> <fct>
1 20180714samharris.pdf 100 2. Psychology
2 20180714samharris.pdf 0 1. Creativity
3 20180724randomshow.pdf 54 2. Psychology
4 20180724randomshow.pdf 40 6. Business
5 20180746randomshow.pdf 53 2. Psychology
6 20180746randomshow.pdf 45 6. Business
7 20180787samharris.pdf 100 2. Psychology
8 20180787samharris.pdf 0 6. Business
9 201808107jockowillink.pdf 87 2. Psychology
10 201808107jockowillink.pdf 13 5. Mindfullness
11 201808129randomshow.pdf 75 4. Health
12 201808129randomshow.pdf 18 6. Business
13 201808146randomshow.pdf 80 4. Health
14 201808146randomshow.pdf 11 6. Business
15 20180907stephendubner.pdf 73 6. Business
16 20180907stephendubner.pdf 14 1. Creativity Disclaimers, Redux
This is not an NLP “how to.” If you want one of those, you should checkout the resource I more or less copied from Tidy Text Mining.
This is a prototype. I plan to eventually analyze all Tim Ferriss episodes to develop more comprehensive topics.
To Tim Ferriss, if by chance you’re reading this, please let me know if I’ve violated your Terms of Use, and I’d be happy to modify or take down. Also, thanks for reading!